Conditional Image Generation with Classifier Guidance¶
Introduction. In our previous tutorial, we showed how we can build an image generation machine. While that is pretty cool, it is not quite useful yet. Generating some image is not interesting, usually we want to control our generation process. We want to say something like: "give me an image with a cat on it" and then get an image of a cat. In the next 2 tutorials, we are going to show you 2 techniques to achieve our goal: 1. Classifier guidance and 2. Classifier-free guidance. Today, we are going to focus on classifier guidance.
Let's formalize our goal. In this case, we want to sample an image $x$ specified under a goal variable $y$. E.g. $x$ could be an image of a handwritten digit, and $y$ is a class, e.g. the digit the image represents. Formally, we want to sample from the distribution $p(x|y)$ (the conditional distribution of $x$ given $y$). For example, if we set $y=4$, we want to sample novel images of 4's.
Why does our previous approach not work? It is important to understand that in principle we could very easily sample from $p(x|y)$ with our previous (unconditional) diffusion model approach. We simple train the model on data (i.e. images) $x$ whose label is $y$. However, that would have two disadvantages:
- Many more models: We would need to have a model for every class label $y$. This makes the dataset significantly smaller per model and we would need train a lot of models. Even worse, if $y$ is arbitrary text, then it is virtually impossible to train a model for every instance of $y$.
- No cross-context learning: intuitively, you would want to have a model that leverages its learnings across class labels $y$. That would allow you to use much more data - which is always a good bet in machine learning :)
Classifier guidance. Let's consider the task of sampling from the distribution $p(x|y)$ with diffusion models. Again, we would convert the data distribution $p_{0}(x|y)=p(x|y)$ into a noised distribution $p_{1}(x|y)$ gradually over time via an SDE with $X_t\sim p_{t}(x|y)$ for all $0\leq t \leq 1$. As we have learnt in our previous tutorials, we need an approximation of the score function $\nabla_{x}\log p_t(x|y)$ to reverse the noising process and to sample from $p_{0}(x|y)=p(x|y)$. Let's use Bayes' rule to compute: $$ p_t(x|y) = \frac{p_t(y|x)p_t(x)}{p_t(y)}$$ And therefore, $$ \begin{align*} \log p_t(x|y) =& \log(p_t(y|x)) + \log(p_t(x)) - \log(p_t(y)) \end{align*} $$ Taking the gradient gives: $$ \begin{align*} \nabla_{x} \log p_t(x|y) =&\nabla_{x}\log(p_t(y|x)) + \nabla_{x}\log(p_t(x)) - \nabla_{x}\log(p_t(y)) \\ =&\nabla_{x}\log(p_t(y|x)) + \nabla_{x}\log(p_t(x)) \end{align*}$$ The above term is very significant. The second term is basically our unconditional score model $\nabla_{x}\log(p_t(x))$. In other words, this is what we have already trained beforehand! Therefore, we only need a way to compute the first term. Let's look at a bit closer. The term $p_t(y|x))$ is the probability of $y$ given $x$ at time $t$. This conditional probability is basically what we learn when we train a classifier of $y$ given $x$, i.e. of predicting the label $y$ given a noised data point $x$. In practice, we often end up using a more sharp distribution $p_{t}(y|x)^s$ for a factor $s\geq 0$. Therefore, we use: $$ \begin{align*} \nabla_{x} \log p_t(x|y) =&s\nabla_{x}\log(p_t(y|x)) + \nabla_{x}\log(p_t(x)) \end{align*}$$ for a parameter $s$ that tunes how strong the classifier gradient should be. Even if you do not understand the above derivation, this term is very intuitive: classifier guidance changed the score to not only point into regions of high probability $p_t(x)$ but pushes into regions where also $p_t(y|x)$ is high.
In sum, we simply need to do the following for conditional generation:
Training:
- Train an unconditional score model $s_{\theta}(x_t,t)=\nabla_{x}\log(p_t(x))$ (see previous tutorial)
- Train a train a classifier $q_{\phi}(y|x,t)$ of $y$ given $x$ - where $\phi$ are the parameters of our neural network and $x$ is a sample from $p_{t}$.
Sampling: At every time step, compute
- Unconditional score $s_{\theta}(x_t,t)\approx \nabla_{x}\log(p_t(x))$
- Gradient of conditional probability $\nabla_{x}\log q_{\phi}(y|x,t) \approx \nabla_{x}\log p_t(y|x)$.
- Run a diffusion time step with $s_{\theta}(x_t,t) + s\nabla_{x}\log q_{\phi}(y|x,t)$.
The crucial insight here is that for conditional generation, we only need to train an additional classifier on our noisy data $p_{t}(x)$ and we are done - without every needing the re-train our unconditional diffusion model!
%load_ext autoreload
%autoreload 2
import numpy as np
import matplotlib.pyplot as plt
from typing import Callable, List
from itertools import product
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
import numpy as np
from IPython.display import HTML
import seaborn as sns
from IPython.display import Video
import os
import pandas as pd
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
from torch.utils.data import Dataset
from torch import Tensor
from abc import ABC, abstractmethod
from torch.nn.functional import relu
from torch.utils.data.dataloader import DataLoader
from tqdm.notebook import tqdm
import scipy.stats as st
from sde import VPSDE, ItoSDE
from train import train_diffusion_model
from sampling import run_backwards
import torch.nn.functional as F
from torch.optim.lr_scheduler import LRScheduler
Define SDE¶
As in previous tutorials, let's define our variance-preserving SDE:
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
sde = VPSDE(T_max=1,beta_min=0.01, beta_max=10.0)
Load MNIST data¶
image_size = 28
classes_by_index = np.arange(0,10).astype('str')
transform = transforms.Compose([transforms.Resize(image_size),\
transforms.ToTensor(),\
transforms.Normalize([0.5],[0.5])]) #Normalize to -1,1
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
testset = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
batch_size = 256
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=True, num_workers=2)
Train an MNIST classifier on noised data¶
Next, we define a classification model. We are taking a straight-forward image convolutional neural network but add a time component, we simply concatenate the time component to our input before the fully connected layer.
class MNISTClassifier(nn.Module):
"""Code from: https://nextjournal.com/gkoehler/pytorch-mnist"""
def __init__(self):
super(MNISTClassifier, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x, t):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(x + t[:,None])
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x)
Next, let's train the classification: we sample a random time $t\in [0,1]$ and a random $x\sim p_0(x)$ and its label $y$. Next, we create $x_t$ from $x$ by running the SDE, i.e. the noised version of $x$ after running the SDE for some time $t$. Finally, we put it in our classifier and compute the cross-entropy loss.
def train_diffused_classifier(model, sde: ItoSDE, dataloader: DataLoader, optimizer, device, n_epochs: int, print_every: int, scheduler: LRScheduler = None):
model.train()
model = model.to(DEVICE)
running_loss_list = []
lr_list = []
for epoch in range(n_epochs):
print(f"Epoch: {epoch}")
running_loss = 0.0
for idx, (x_inp,target) in tqdm(enumerate(dataloader), total=len(dataloader)):
#Zero gradients:
optimizer.zero_grad()
#Run forward samples:
X_t,noise,score,time = sde.run_forward_random_times(x_inp)
#Send to device:
X_t = X_t.to(DEVICE)
noise = noise.to(DEVICE)
time = time.to(DEVICE)
#Predict score:
model_pred = model(X_t,time)
#ONLY THIS LINE CHANGED TO BEFORE: we train the model to minimize the negative log-likelihood:
loss = F.nll_loss(model_pred, target.to(DEVICE))
#Optimize:
loss.backward()
optimizer.step()
if scheduler is not None:
scheduler.step()
# print statistics
running_loss += loss.detach().item()
if (idx+1) % print_every == 0:
avg_loss = running_loss/print_every
running_loss_list.append(avg_loss)
running_loss = 0.0
if scheduler is not None:
print(f"Loss: {avg_loss:.4f} | {scheduler.get_lr()}")
lr_list.append(scheduler.get_lr())
else:
print(f"Loss: {avg_loss:.4f}")
return model,running_loss_list
LEARNING_RATE = 1e-3 #2e-5
WEIGHT_DECAY = 0.0
N_EPOCHS = 500
TRAIN_SCORE = False
RETRAIN = False
classifier = MNISTClassifier()
if RETRAIN:
optimizer = torch.optim.AdamW(classifier.parameters(),lr=LEARNING_RATE, weight_decay=WEIGHT_DECAY,maximize=False)
scheduler=torch.optim.lr_scheduler.OneCycleLR(optimizer,LEARNING_RATE,total_steps=N_EPOCHS*len(trainloader),pct_start=0.25,anneal_strategy='cos')
classifier,running_loss_list = train_diffused_classifier(classifier, sde, trainloader, optimizer=optimizer, scheduler=scheduler, device=DEVICE, n_epochs=N_EPOCHS, print_every=100)
torch.save(classifier.state_dict(),"20231127_mnist_diffusion_classifier.ckpt")
else:
classifier_state_dict = torch.load("20231127_mnist_diffusion_classifier.ckpt")
classifier.load_state_dict(classifier_state_dict)
classifier = classifier.to(DEVICE)
Let's plot how the distribution $q_{\phi}(y|x_t,t)$ changes over time $0\leq t\leq 1$. Intuitively, at time $t$, we have not added any noise. Therefore, $x_t=x$ and we should have very confidence about the label. If $t=1$, the image is basically noise and we should have very low confidence. Below, you can see exactly that happening. The larger $t$ becomes, the more uniform the distribution $q_{\phi}(y|x_t,t)$ is becoming.
n_grid_points = 16
time_vec = torch.linspace(0,1,n_grid_points)**2
X_0, Y = trainset.__getitem__(23410)
X_0 = torch.stack([X_0.unsqueeze(0).squeeze()]*n_grid_points)
X_t, noise, score = sde.run_forward(X_0,time_vec)
X_t = X_t.unsqueeze(1)
results = np.exp(classifier(X_t.to(DEVICE),time_vec.to(DEVICE)).cpu().detach().numpy())
fig, axs = plt.subplots(2, len(results),figsize=(3*len(results),6))
for idx in range(len(results)):
axs[0,idx].set_title(f"Prediction distribution \n time = {time_vec[idx]:.3f}")
axs[0, idx].bar(x=classes_by_index, height=results[idx])
axs[1, idx].set_title(f"Input image at t={time_vec[idx]:.2f}")
axs[1, idx].imshow(X_t[idx].squeeze(), cmap='grey')
/tmp/ipykernel_401506/4223319117.py:19: UserWarning: Implicit dimension choice for log_softmax has been deprecated. Change the call to include dim=X as an argument. return F.log_softmax(x)

Compute classifier gradient¶
Next, we want to compute the classifier gradient $\nabla_{x_t}\log q_{\phi}(y|x_t,t)$. In order to do so, we use the pytorch automatic differentiation framework to compute $\nabla_{x}\log q_{\phi}(y|x)$. We do the following:
- Convert x into a tensor that has
requires_grad=Trueto signal pytorch to compute gradients. - Send both x and t to GPUs
- Pass them through the classifier. Note that the classifier compute $\log q_{\phi}(y|x)$ for every possible $y=0,1,2,3,4,5,6,7,9$.
- Therefore, we need to select the one that we want by selecting for the target $y_0=y$.
- Finally, we sum up: $$\sum\limits_{i=1}^{B}\log p_t(y_0|x_i)$$ where $B$ is the batch size.
- Finally, we take the gradient of the sum which gives us $\nabla_{x_i}q_{\phi}(y_0|x_i)$ for each element in the batch.
def get_classifier_gradient(x: torch.Tensor, t: torch.Tensor, target: int, scale_factor: float = 8.0):
classifier.zero_grad()
x = torch.nn.Parameter(x.to(DEVICE),requires_grad=True)
t = t.to(DEVICE)
output = classifier(x,t)
output[:,target].sum().backward()
return scale_factor*x.grad.detach()
Let's visualize the gradient:
X_0, Y = trainset.__getitem__(23410)
X_0 = torch.stack([X_0.unsqueeze(0).squeeze()]*n_grid_points)
X_t, noise, score = sde.run_forward(X_0,time_vec)
X_t = X_t.unsqueeze(1)
fig, axs = plt.subplots(2,16,figsize=(16*4,4))
for idx in range(16):
gradient = get_classifier_gradient(X_t[idx].unsqueeze(0), torch.tensor([0.05]), Y)
axs[0,idx].imshow(gradient.detach().cpu().numpy().squeeze())
axs[1,idx].imshow(X_t[idx].squeeze())
/tmp/ipykernel_401506/4223319117.py:19: UserWarning: Implicit dimension choice for log_softmax has been deprecated. Change the call to include dim=X as an argument. return F.log_softmax(x)

Conditional Sampling¶
Finally, let's perform conditional generation. We modified our run_backwards function to take two arguments:
-
cond_grad_func: a conditional gradient function, which isget_classifier_gradienthere. This is $s\nabla_{x_t}q_{\phi}(y_0|x_t,t)$. -
target: an integer $y_0$ giving the label that we want to condition on.
We then run the diffusion backwards in the same way as before. The only lines of code that changes are:
if cond_grad_func is not None:
cond_grad = cond_grad_func(x.to(device), time_vec.to(device), target).to(change.device)
cond_grad = (step_size*ItoSDE._mult_first_dim(g_squared,cond_grad))
change += cond_grad
next_step = x + change
that add $s*g^{2}(t)\nabla_{x}q_{\phi}(y|x)$ to our score (multiplied by the step_size).
Therefore, let's load the unconditional score model $s_{\theta}(x_t,t)$ that we trained in the previous tutorial:
from unet import Unet
def load_mnist_model():
model = Unet(base_dim=28, in_channels=1, out_channels=1, time_embedding_dim=256, timesteps=100, dim_mults=[2, 4], temp=100.0)
model = torch.compile(model)
model_state_dict = torch.load("20231120_mnist_diffusion_denoiser.ckpt")
model.load_state_dict(model_state_dict)
model = model.to(DEVICE)
return model
model = load_mnist_model()
Let's sample:
# torch._dynamo.config.verbose=True
# torch._dynamo.config.suppress_errors = True
single_target_shape = [8,1,image_size,image_size]
output_list = []
for target in classes_by_index:
x_start = torch.clip(torch.randn(size=single_target_shape),-1.0,1.0)
output,time_grid = run_backwards(model,sde,x_start=x_start,n_steps=1000,device=DEVICE,train_score=TRAIN_SCORE, clip_min=-10.0, clip_max=10.0, cond_grad_func=get_classifier_gradient, target=int(target))
output_list.append(output)
output_agg = torch.stack([output.transpose(1,0) for output in output_list],dim=1)
0it [00:00, ?it/s]/tmp/ipykernel_401506/4223319117.py:19: UserWarning: Implicit dimension choice for log_softmax has been deprecated. Change the call to include dim=X as an argument. return F.log_softmax(x) 1000it [00:20, 47.87it/s] 1000it [00:09, 107.63it/s] 1000it [00:09, 107.80it/s] 1000it [00:09, 106.99it/s] 1000it [00:09, 107.46it/s] 1000it [00:09, 106.98it/s] 1000it [00:09, 107.48it/s] 1000it [00:09, 108.97it/s] 1000it [00:09, 108.89it/s] 1000it [00:09, 105.21it/s]
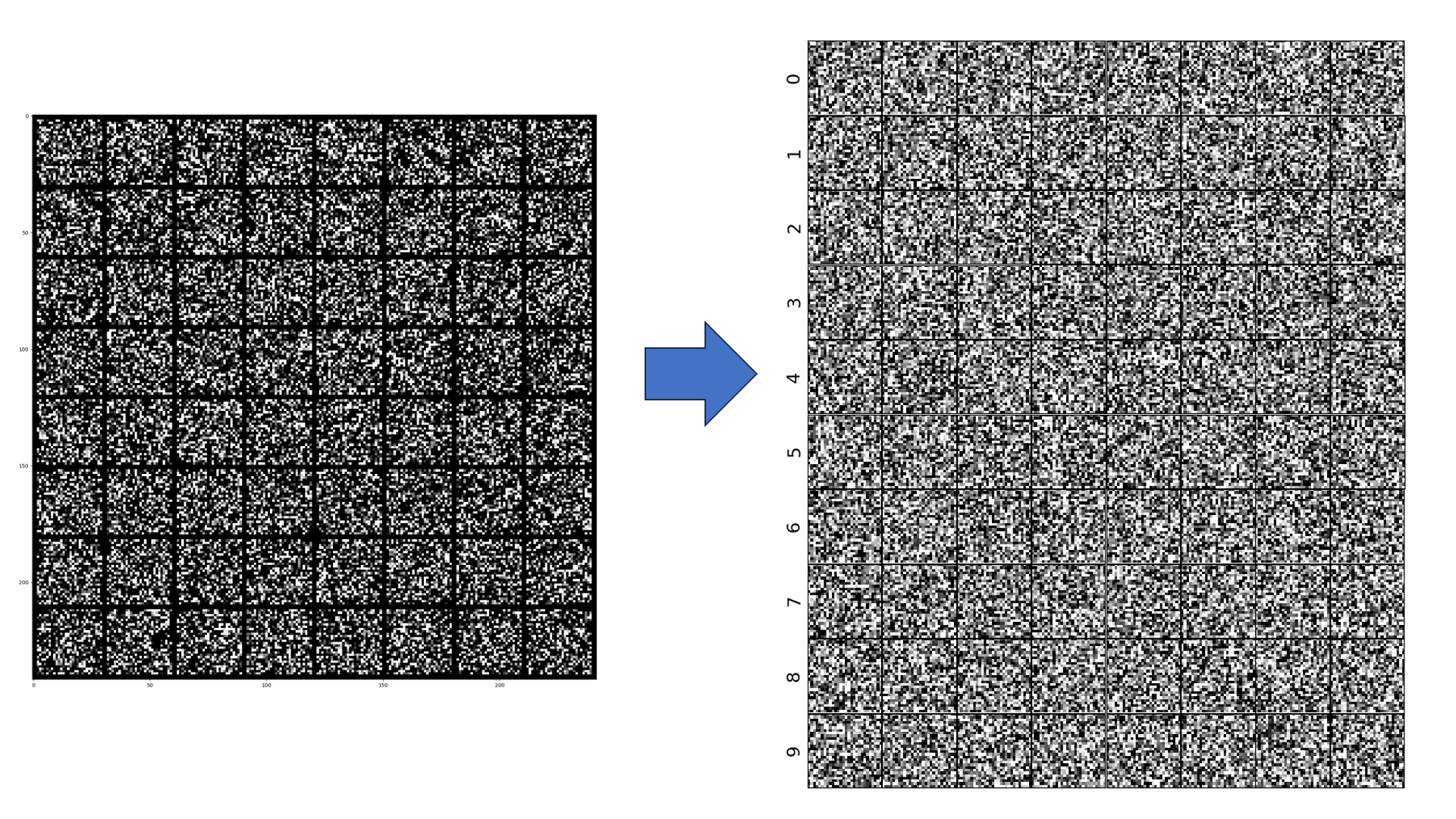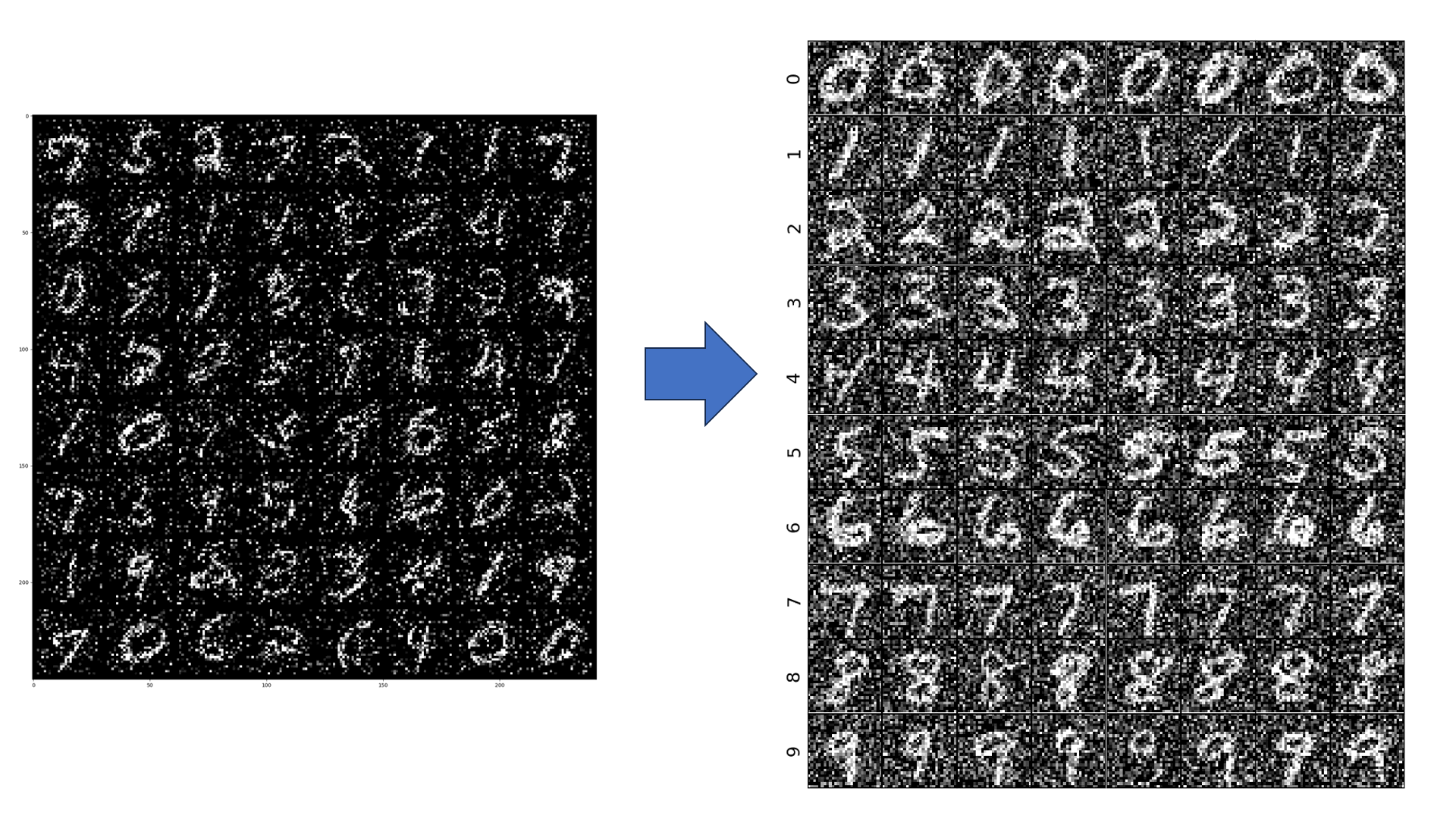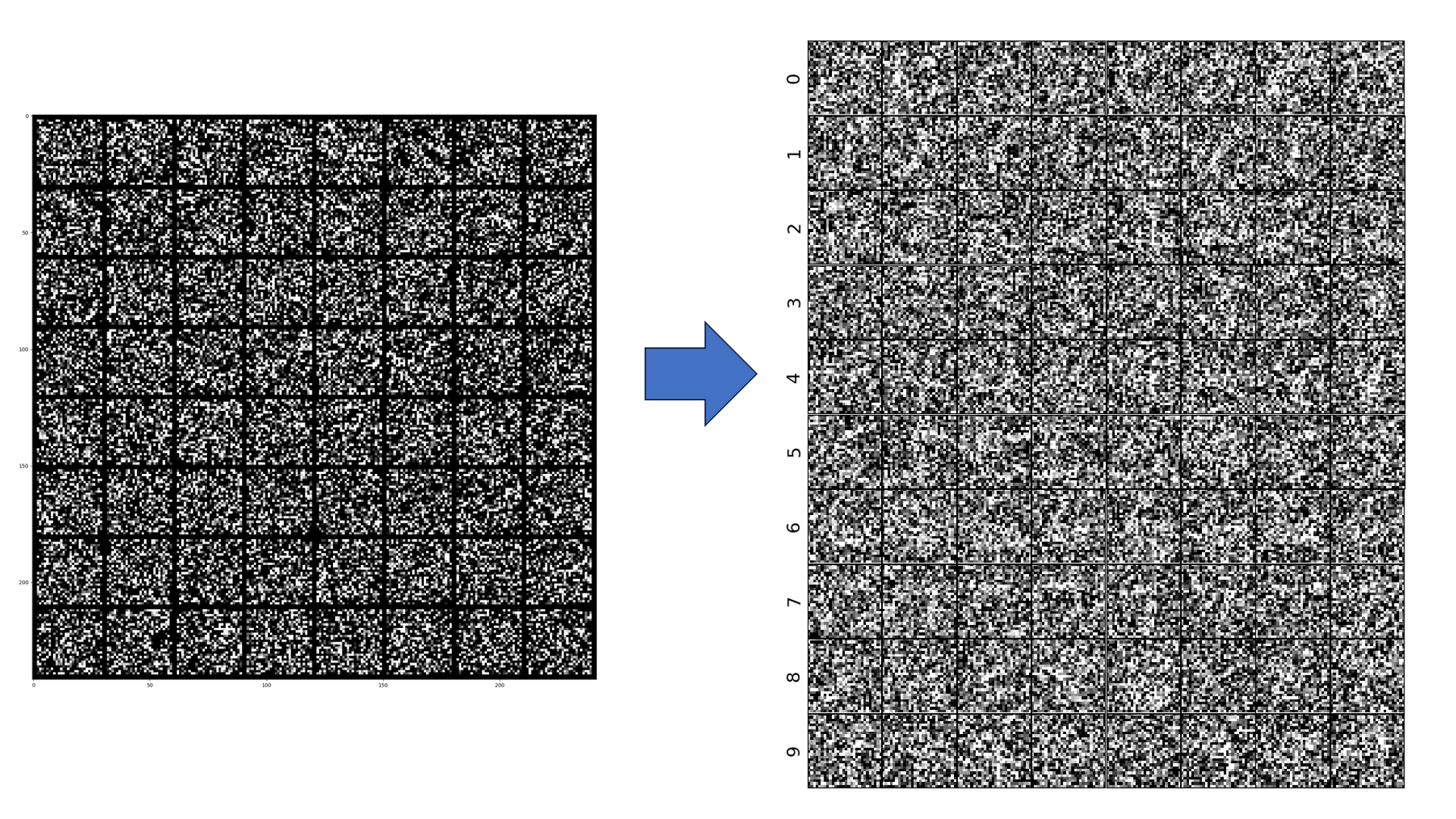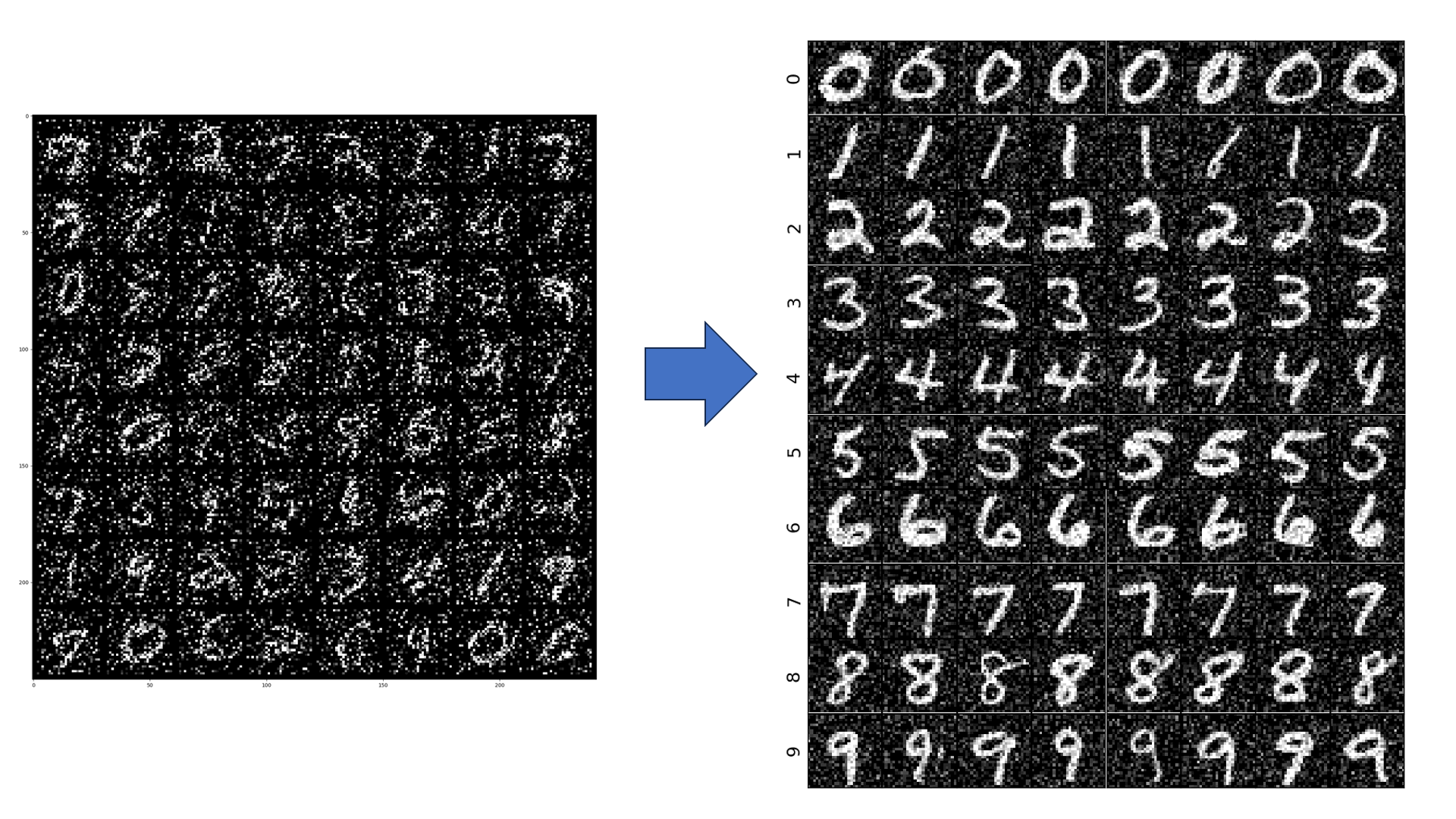
Visualize results¶
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.axes_grid1 import ImageGrid
n_time_steps = output_agg.shape[0]
n_labels = output_agg.shape[1]
images_per_label = output_agg.shape[2]
time_idx = -1
#fig, axs = plt.subplots(n_labels, images_per_label)
grid_idx = 0
fig = plt.figure(figsize=(12., 12.))
grid = ImageGrid(fig, 111, # similar to subplot(111)
nrows_ncols=(n_labels, images_per_label), # creates 2x2 grid of axes
axes_pad=0.01, # pad between axes in inch.
)
for label in range(n_labels):
for image_idx in range(images_per_label):
grid[grid_idx].imshow(output_agg[time_idx,label,image_idx].squeeze(),cmap='grey')
grid[grid_idx].set_xticks([])
grid[grid_idx].set_yticks([])
grid[grid_idx].set_ylabel(f"{label}",fontsize=16)
grid_idx += 1

Finally, let's make a cool gif out of it.
from PIL import Image
def make_gif(output_agg):
n_images = 20
n_time_steps = output_agg.shape[0]
time_jumps = n_time_steps//n_images
time_idx_list = [i * time_jumps for i in range(n_images)] + [n_time_steps-1]
image_paths = []
n_labels = output_agg.shape[1]
images_per_label = output_agg.shape[2]
for time_idx in time_idx_list:
#fig, axs = plt.subplots(n_labels, images_per_label)
grid_idx = 0
fig = plt.figure(figsize=(12., 12.))
grid = ImageGrid(fig, 111, # similar to subplot(111)
nrows_ncols=(n_labels, images_per_label), # creates 2x2 grid of axes
axes_pad=0.01, # pad between axes in inch.
)
for label in range(n_labels):
for image_idx in range(images_per_label):
grid[grid_idx].imshow(output_agg[time_idx,label,image_idx].squeeze().clip(-1,1),cmap='grey')
grid[grid_idx].set_xticks([])
grid[grid_idx].set_yticks([])
grid[grid_idx].set_ylabel(f"{label}",fontsize=16)
grid_idx += 1
filepath = f"mnist_cond_gen_idx={time_idx}.png"
plt.savefig(filepath)
image_paths.append(filepath)
frames = [Image.open(image) for image in image_paths+[image_paths[-1]]*min(len(image_paths),10)]
frame_one = frames[0]
frame_one.save("MNIST_conditional_diffusion.gif", format="GIF", append_images=frames,
save_all=True, duration=100, loop=0)
for image_path in image_paths:
os.remove(image_path)
from IPython.utils import io
with io.capture_output() as captured:
make_gif(output_agg)
from IPython.display import HTML
HTML('<img src="/assets/animation/MNIST_conditional_diffusion.gif"">')
